一段鬼畜的代码
有个“国际 C 语言混乱代码大赛”,简称 IOCCC,画风简直鬼畜。其中有个获奖代码是这样的:1
main(_){_^448&&main(-~_);putchar(--_%64?32|-~7[__TIME__-_/8%8][">'txiZ^(~z?"-48]>>";;;====~$::199"[_*2&8|_/64]/(_&2?1:8)%8&1:10);}
这段代码直接复制粘贴编译运行就输出了当前时间!
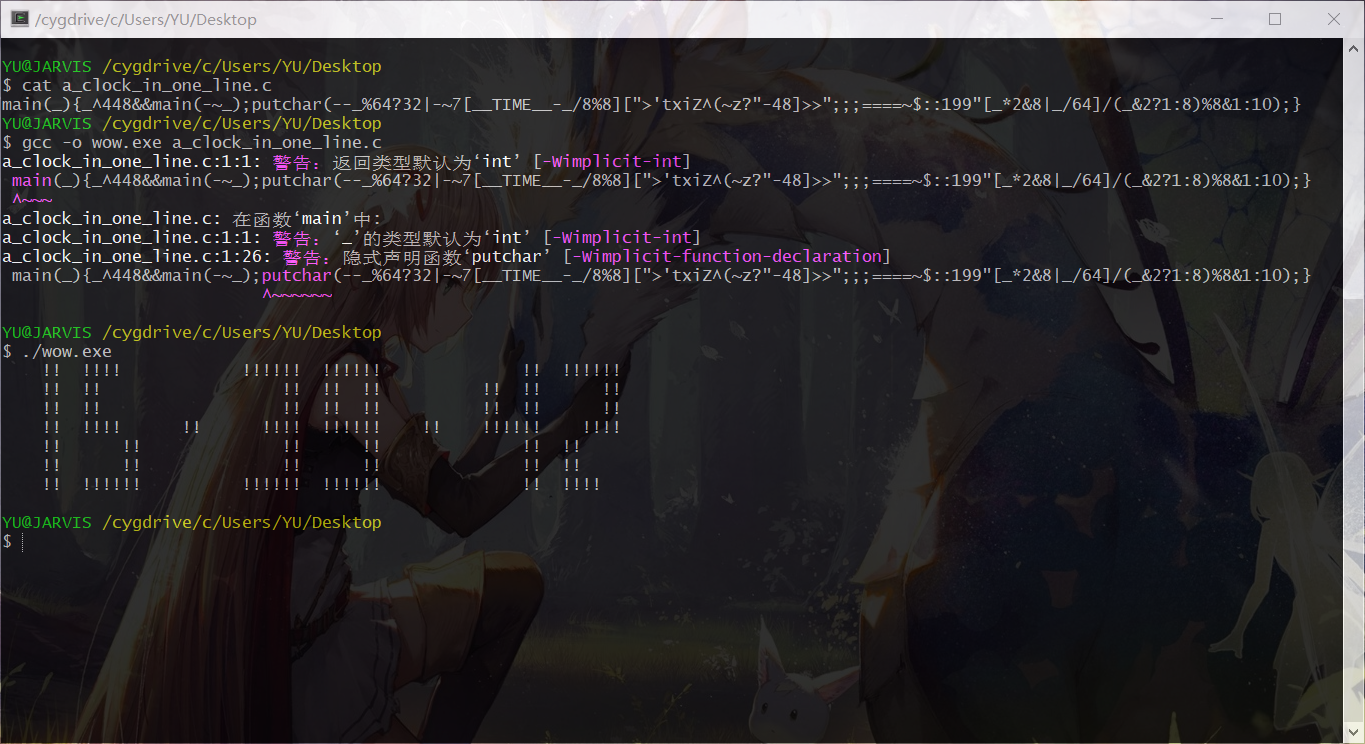
C 语言果然是强大而灵活。QAQ
注意到源码中有 __TIME__ ,这是预处理器定义的特殊宏,它能扩展为一个字符串,内容为预处理器运行的时间,格式为 "HH:MM:SS"。
好奇心驱使着我想要一探究竟。
首先,格式化代码并加入头文件及返回值:1
2
3
4
5
6
7
8
9
int main(_)
{
_ ^ 448 && main(-~_);
putchar(--_ % 64 ? 32 | -~7[__TIME__ - _ / 8 % 8][">'txiZ^(~z?" - 48] >> ";;;====~$::199"[_ * 2 & 8 | _ / 64] / (_ & 2 ? 1 : 8) % 8 & 1 : 10);
return 0;
}
展开逻辑与的短路特性,引入变量并化简:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main(int i)
{
if (i ^ 448)
main(-~i);
if (--i % 64)
{
char a = -~7[__TIME__ - i / 8 % 8][">'txiZ^(~z?" - 48];
char b = ";;;====~$::199"[i * 2 & 8 | i / 64] / (i & 2 ? 1 : 8) % 8;
char c = a >> b;
putchar(32 | (c & 1));
}
else
putchar(10);
return 0;
}
接下来展开各种位运算并用字符 '\n' 代替其 ASCII 码值 10 :
if (i ^ 448)等价于if (i != 448)-~i等价于i + 1
1 |
|
递归化为循环,这个有点烧脑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main(void)
{
for (int i = 447; i >= 0; i--)
if (i % 64)
{
char a = 1 + 7[__TIME__ - i / 8 % 8][">'txiZ^(~z?" - 48];
char b = ";;;====~$::199"[i * 2 & 8 | i / 64] / (i & 2 ? 1 : 8) % 8;
char c = a >> b;
putchar(32 | (c & 1));
}
else
putchar('\n');
return 0;
}
注意到 putchar(32 | (c & 1)) 取决于 c 的奇偶性,32 的二进制表示为 0010 0000 ,若 c 为奇数则 putchar(33) 否则putchar(32) 。再分别用字符替换其 ASCII 码值,得到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main(void)
{
for (int i = 447; i >= 0; i--)
if (i % 64)
{
char a = 1 + 7[__TIME__ - i / 8 % 8][">'txiZ^(~z?" - 48];
char b = ";;;====~$::199"[i * 2 & 8 | i / 64] / (i & 2 ? 1 : 8) % 8;
char c = a >> b;
if (c % 2)
putchar('!');
else
putchar(' ');
}
else
putchar('\n');
return 0;
}
接下来,开始分析最长的那两行!
C 语言中 a[b] 等价于 b[a] ,这是 C 语言指针的基础知识,于是有:1
2char a = 1 + (__TIME__ - i / 8 % 8)[7][">'txiZ^(~z?" - 48]; // 第一次嵌套
char a = 1 + (">'txiZ^(~z?" - 48)[(__TIME__ - i / 8 % 8)[7]]; // 第二次嵌套
得到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main(void)
{
for (int i = 447; i >= 0; i--)
if (i % 64)
{
char a = (">'txiZ^(~z?" - 48)[(__TIME__ - i / 8 % 8)[7]] + 1;
char b = ";;;====~$::199"[i * 2 & 8 | i / 64] / (i & 2 ? 1 : 8) % 8;
char c = a >> b;
if (c % 2)
putchar('!');
else
putchar(' ');
}
else
putchar('\n');
return 0;
}
注意到 (i & 2 ? 1 : 8) 取决于 i & 2 的值,展开得到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main(void)
{
for (int i = 447; i >= 0; i--)
if (i % 64)
{
char a = (">'txiZ^(~z?" - 48)[(__TIME__ - i / 8 % 8)[7]] + 1;
char b = ";;;====~$::199"[i * 2 & 8 | i / 64];
if ((i & 2) == 0) //i & 2 一定要加括号
b /= 8;
b %= 8;
char c = a >> b;
if (c % 2)
putchar('!');
else
putchar(' ');
}
else
putchar('\n');
return 0;
}
这里 char a 这一行很奇怪,字符串减去一个整数再取下标?!先写两个 demo 看看是什么情况(当前时间 18:47):1
2
3
4
5
6
7
8
int main(void)
{
char a = (__TIME__ - 7)[7];
printf("%c\n", a);
return 0;
}
编译通过!运行发现输出1。
__TIME__的第一位字符?1
2
3
4
5
6
7
8
int main(void)
{
char a = (__TIME__ - 6)[7];
printf("%c\n", a);
return 0;
}
运行发现输出8。
__TIME__的第二位字符?
所以,(__TIME__ - i)[7] 等价于 (__TIME__)[7 - i] ?
事实上,这里不能把源代码中的字符串看成数组而应该看成指针。
下标操作默认是 a[i] = *(a + i) 实现的,当然也就有 (a + n)[i] 等价于 a[i + n]。
至此,程序分析到这一步:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main(void)
{
for (int i = 447; i >= 0; i--) // 一共7行,每行64个字符,一共循环7x64=448次
if (i % 64) // 每输出64个字符就换行
{
char a = ">'txiZ^(~z?"[__TIME__[7 - i / 8 % 8] - 48] + 1;
char b = ";;;====~$::199"[i * 2 & 8 | i / 64];
if ((i & 2) == 0)
b /= 8;
b %= 8;
char c = a >> b;
if (c % 2)
putchar('!');
else
putchar(' ');
}
else
putchar('\n');
return 0;
}
分析不下去了。
上网找吧,找到了一篇分析得比较好的文章:StackOverflow
更新:
时隔两年……我更新了!
写这篇文章的时候我才大二,不是不更新,而是觉得那篇英文回答已经说清楚了。现在毕业了,看到评论居然还有催更的……虽然现在也很忙,但是我试着把这代码最困难的部分用我的方式分析一下吧,可能需要有一定的 C 语言基础才能理解。就当感谢给我点赞、收藏和评论的人。
首先把可读性提高一点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
int main(void)
{
const int chars_per_line = 64; // The number of characters per line
const int chars_total = chars_per_line * 7; // There are 448 characters in total
for (int i = chars_total - 1; i >= 0; i--) // i: 447, 446, 445, ..., 2, 1, 0.
{
if (i % chars_per_line) // Wrap every 64 characters
{
char t = __TIME__[7 - i / 8 % 8]; // char: "0123456789:" -> ASCII: 48-58
char a = ">'txiZ^(~z?"[t - '0'] + 1; // '0'->'>', '1'->''', '2'->'t'......, ':'->'?'
char b = ";;;====~$::199"[((i * 2) & 8) | (i / chars_per_line)];
if ((i & 2) == 0)
{
b >>= 3; // Shift right 3 bits
}
b &= 7; // Get lower 3 bits
char c = a >> b;
putchar((c & 1) ? '!' : ' ');
}
else
{
putchar('\n');
}
}
return 0;
}
可以看到重点是a b两个变量,先来分析a。
写一段 Python 程序来分析一下 char a = ">'txiZ^(~z?"[t - '0'] + 1; 的结果:1
2
3for time_digit in "0123456789:":
a = ord(">'txiZ^(~z?"[ord(time_digit) - ord('0')]) + 1
print("'{}' -> ".format(time_digit)+"{:0>8b}".format(a)[:4]+" "+"{:0>8b}".format(a)[4:])
输出:1
2
3
4
5
6
7
8
9
10
11'0' -> 0011 1111
'1' -> 0010 1000
'2' -> 0111 0101
'3' -> 0111 1001
'4' -> 0110 1010
'5' -> 0101 1011
'6' -> 0101 1111
'7' -> 0010 1001
'8' -> 0111 1111
'9' -> 0111 1011
':' -> 0100 0000
注意到最高位都是 0,剩下七位暂时看不出规律,应该需要结合b进行分析,先放在这。
再写一段 Python 程序看一下 char b = ";;;====~$::199"[((i * 2) & 8) | (i / chars_per_line)]; 的结果:1
2
3
4
5i = 0
for b in ";;;====~$::199\0":
print("[{:0>2}] {:2} -> ".format(i, (b if b != '\0' else "\\0")) +
"{:0>8b}".format(ord(b))[:4]+" "+"{:0>8b}".format(ord(b))[4:])
i += 1
输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[00] ; -> 0011 1011
[01] ; -> 0011 1011
[02] ; -> 0011 1011
[03] = -> 0011 1101
[04] = -> 0011 1101
[05] = -> 0011 1101
[06] = -> 0011 1101
[07] ~ -> 0111 1110
[08] $ -> 0010 0100
[09] : -> 0011 1010
[10] : -> 0011 1010
[11] 1 -> 0011 0001
[12] 9 -> 0011 1001
[13] 9 -> 0011 1001
[14] \0 -> 0000 0000
注意到最高位仍然都是 0,其他的暂时看不出明显的规律,继续。1
2
3
4
5if ((i & 2) == 0)
{
b >>= 3; // Shift right 3 bits
}
b &= 7; // Get lower 3 bits
这几行是根据i的值对b进行取位操作。
如果i的次低位为 0 则取b的中间三位(3、4、5 位),否则取低三位(0、1、2 位)。
再写一段 Python 程序看一下b最后的结果:1
2
3
4
5
6
7
8
9
10chars_per_line = 64
chars_total = chars_per_line * 7
for i in range(chars_total-1, 0-1, -1):
b = ord(";;;====~$::199\0"[((i * 2) & 8) | (i // chars_per_line)])
if (i & 2) == 0:
b >>= 3
b &= 7
print(b, end="")
if i % 64 == 0:
print()
输出:1
2
3
4
5
6
70000557700005577000055770000557700005577000055770000557700005577
1177557711775577117755771177557711775577117755771177557711775577
1177557711775577117755771177557711775577117755771177557711775577
1166557711665577116655771166557711665577116655771166557711665577
2277337722773377227733772277337722773377227733772277337722773377
2277337722773377227733772277337722773377227733772277337722773377
4444337744443377444433774444337744443377444433774444337744443377
有眉目了!都是重复的 7 行 8 列的某种 bitmap。
取其中一组来看:1
2
3
4
5
6
700005577
11775577
11775577
11665577
22773377
22773377
44443377
还记得前面的最高位都是 0 吗?最高位也就是第 7 位(从 0 开始数),如果我们把 7 换成空格,当当当当!1
2
3
4
5
6
7000055
11 55
11 55
116655
22 33
22 33
444433
很明显了,七段数码管。
七段数码管显示数字是靠的是一些段亮,一些段不亮,比如,如果要显示 0,那么上面这个七段数码管的 012345 都要亮,而 6 不能亮:1
2
3
4
5
6
7000055
11 55
11 55
11 55
22 33
22 33
444433
所以,a只可能是段选,回去验证一下,'0' -> 0011 1111,正好是 012345 位置一,第 6 位(从最低位第 0 位开始数)置零!
再比如要显示 9,那么应该是这样的:1
2
3
4
5
6
7000055
11 55
11 55
116655
33
33
444433
除最高位外,第二位置零,其他位置一,而前面a的输出:'9' -> 0111 1011。Yes!
好了,最主要的部分就分析到这里够了。
其余的是一些细枝末节的小问题,我相信如果都看到这里了那些小问题肯定不在话下,所以我就不再赘述了(才不是因为懒)。
我在源码里以注释的形式进行了详细的分析,源码:a_clock_in_one_line_analysis.c